

Most enterprises spent a decade mastering structured data. Then GenAI arrived and quietly shifted the center of gravity. The smartest AI in your stack does its best work on text, documents, emails, tickets, chats, specs, and transcripts. In other words, unstructured data.
Treat it like a second-class citizen and your AI will underperform. Treat it like a strategic asset and it becomes a competitive advantage.
At a glance: structured vs unstructured data

Format
- Structured data: rows and columns, fixed schema, SQL friendly
- Unstructured data: documents, files, messages, PDFs, audio, video, images, web pages
AI impact
- Structured data: great for metrics and triggers
- Unstructured data: essential for reasoning, summarization, retrieval, and agentic actions
Meaning
- Structured data: explicit fields, limited context
- Unstructured data: implicit context, relationships and nuance live in the content
Change velocity
- Structured data: planned updates, governed schemas
- Unstructured data: constant edits, conflicting versions, knowledge drift
Typical tools
- Structured data: warehouses, ETL, BI, MDM
- Unstructured data: content systems, search, vector stores, LLMs, knowledge graphs

Let’s explore why that difference matters and how to make unstructured data work for GenAI instead of against it.
What is unstructured data?
Unstructured data is where meaning lives, which is why GenAI depends on it. It holds the why and how behind your business. Policies, SOPs, product docs, customer emails, chat logs, contracts, and call transcripts carry intent, nuance, and exceptions that models need to reason. This is the material GenAI was trained to understand.
Since unstructured data doesn’t have an organized structure, it’s harder to search, analyze, and manage. But it often holds valuable insights that can enhance business decision-making when properly processed.
The bottom line is, you should care about unstructured data. Why? Because your most valuable knowledge lives in unstructured data, and both your people and your AI rely on it to do great work.
Why unstructured data is key for AI
All high-value enterprise AI use cases rely on AI’s ability to understand and interact with an organization’s unstructured data.
- Sentiment Analysis: By analyzing customer reviews, support emails, and social media reactions, businesses can gain insights into customer satisfaction and feedback. This helps align business strategies with customer needs and refine your offerings.
- Content Recommendation: In media and entertainment, unstructured data like user preferences and viewing habits can be used to recommend content based on past behavior.
- Fraud Detection: Financial institutions use unstructured data like emails, transaction notes, and social media activity to detect fraud or other suspicious activities.
What makes unstructured hard, and how to manage it
Unstructured data is messy by nature. It is schema-free, context dependent, multimodal, often duplicative, and scattered across systems with inconsistent permissions. It drifts as products, policies, and pricing change. Shelf’s take: solve the hard parts once, upstream. Apply semantic deduplication, version lineage, entity normalization, access controls, and compliance tagging to every asset. Attach trust scores and freshness signals so your RAG pipelines and agents prefer the most reliable source automatically.
- Characteristics to handle well:
- Variability and length: long-form text, mixed formats, images, audio
- Context and intent: meaning depends on role, region, product, and time
- Provenance and governance: who wrote it, when it changed, who can see it
- Contradictions and drift: multiple versions, edits, and exceptions
- Examples that drive AI value:
- Knowledge bases, product docs, runbooks, and SOPs
- Support tickets, live chat, email threads, and call transcripts
- Contracts, policies, regulatory guidance, and audit notes
- Design specs, Jira stories, release notes, and FAQs
Unstructured data examples
Unstructured data comes in a variety of formats and appearing in many industries:
- Customer Support: Emails, chat logs, and support tickets are unstructured data in customer service. Analyzing these can help improve customer satisfaction by identifying common issues and trends.
- Support data: Product catalogs, FAQs, wiki pages, multi-threaded email chains, chat transcripts, call recordings, agent notes, screen captures, and attachments that capture issue context, steps taken, and resolution outcomes.
- Healthcare: Doctor’s notes, medical images like X-rays or MRIs, and patient comments are all examples of unstructured data in healthcare. These require advanced tools to analyze but hold critical information for patient care.
- Media and Entertainment: Audio files, video content, and social media posts are key examples. Extracting insights from these types of data requires specialized software capable of handling text, audio, and visual analysis.
- Legal Documents: Contracts, legal briefs, PDF documents, audio recordings, and case files are unstructured data in the legal field. These documents contain a wealth of information, but extracting key details requires advanced natural language processing (NLP) techniques.
- Retail: Customer reviews, product images, and social media post content are examples of unstructured data in retail. Analyzing this type of data can help businesses understand customer sentiment and improve their products.
The unstructured data stack GenAI actually needs
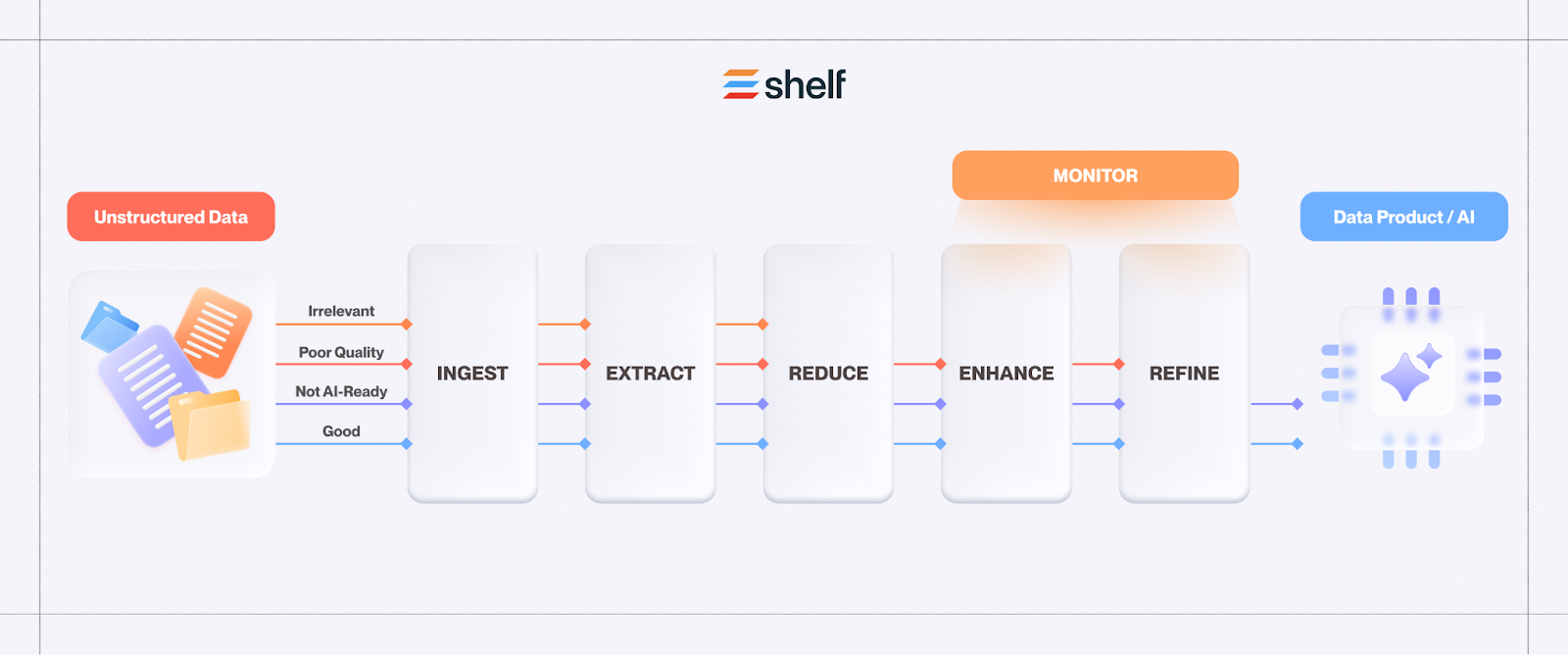
Most teams jump straight to embeddings and a vector database. That is necessary, not sufficient. The winning stack starts earlier and adds intelligence before retrieval.
- Ingest and normalize: connect sources, extract content, OCR, transcribe audio
- Enrich and structure: entity extraction, topic modeling, policy tagging, relationship mapping
- Govern and secure: version control, lineage, permissions, PII redaction
- Index and retrieve: hybrid search, embeddings, knowledge graphs, metadata filters
- Orchestrate and evaluate: prompt routing, grounding, citations, feedback loops, continuous evaluation
Final thought
GenAI rewards teams that take unstructured data seriously. If you want confident agents, trustworthy answers, and measurable ROI, fix the content layer first. The market will keep adding more models and more integrations. The advantage goes to leaders who make their knowledge clean, connected, and contextually intelligent. That is the gap Shelf was built to close.
Shelf Supports Your Unstructured Data
Shelf is a comprehensive solution that manages unstructured data. We operate as the upstream intelligence layer. We transform raw content into context-rich knowledge that flows cleanly into AI, chatbots, agent assist, analytics, and data clouds. Think filter then flow.
The result is higher answer accuracy, fewer hallucinations, and less manual cleanup. Talk to an expert →


